

August 25, 2025
Why We Keep Treating AI Like a Person—and Why It Shouldn’t Run Our Lives (or Our Companies)
Executive Summary
We are living through a strange moment: people know generative AI is just software, and yet we talk to it, trust it, and sometimes let it decide things that matter. That’s a mistake. Today’s models can draft, summarize, and brainstorm at speed—but they still make things up, misread context, and fail silently. When we treat them like people or proxies for judgment, risk goes up.
Here’s the headline picture.
- First, consumer exposure keeps rising: 34% of U.S. adults have used ChatGPT, roughly double since 2023. Younger adults lead the growth.
- Second, organizations are embedding AI fast: 78% reported using AI in at least one function in 2024, up from 55% a year earlier.
- Third, guardrails vary: in one global survey, only 27% of companies that use genAI say all model outputs are reviewed before use; a similar share say 20% or less are checked.
- Fourth, governance is catching up but uneven: a 2025 study finds 77% of organizations are “working on AI governance,” with many still resourcing the basics. Finally, public trust remains brittle: a large Bentley-Gallup study shows 77% of Americans don’t trust businesses to use AI responsibly, though transparency helps.
The core mistake is anthropomorphism plus outsourcing of judgment. We’re wired to see agency in fluent outputs (the ELIZA effect), to prefer mental ease over effort, and to close uncertainty fast. Left unmanaged, those tendencies create automation bias at work: people over-defer to the model, skip verification, and miss context.
The remedy is policy and culture. Treat AI as a power tool—excellent at patterning and draft work—not a proxy for duty of care. Put decision rights on a Red/Amber/Green footing; require human-in-the-loop (HITL) checks where risk is non-trivial; train people on cognitive traps; measure over-reliance; and align with modern frameworks (e.g., NIST’s AI RMF and its Generative AI Profile).
This article lays out the data on how people use genAI, explains why our brains keep treating it like a person, shows why today’s systems cannot shoulder life-level or company-level judgment, and finishes with an executive playbook to keep your workforce from handing the keys to a chatbot.
How People Are Actually Using GenAI
Adoption, frequency, and where people point the tool
Consumer use keeps climbing. As of June 2025, 34% of U.S. adults say they’ve used ChatGPT; the share doubles the 2023 level. Among adults under 30, a majority have tried it. Usage remains lower among older adults and people with less formal education.
In the workplace, the picture is mixed and highly dependent on how surveys phrase “AI use.” Pew finds that about one-in-six U.S. workers (16%) say some of their work is currently done with AI and that most workers don’t use AI regularly at work yet. Other official analyses caution that measurement choices (what counts as AI, whether tools are embedded or explicit) explain much of the spread across surveys; worker-use estimates often range 20–40% with big swings by occupation. Meanwhile, businesses report broader incorporation: the Stanford AI Index notes 78% of organizations using AI in 2024, reflecting a shift from pilots to production.
What are people doing with the tools? Across surveys and enterprise logs, the top categories are predictable: drafting and editing text, summarizing long content, ideation and brainstorming, coding and code explanation, and translation. These are tasks where fast pattern completion helps and stakes are manageable.
Where it helps most: repetitive writing, first-pass outlines, quick explainer notes, and templated code. Where it helps least: tasks that tolerate zero factual error, require up-to-the-minute ground truth, or hinge on tacit context (e.g., “what will persuade this specific stakeholder,” “what our regulator expects in this exact scenario”). These boundaries show up in the data. McKinsey’s 2025 survey finds many companies already redesigning workflows to capture value, but also that review practices vary widely—from “check everything” to “check almost nothing”—which is where over-reliance creeps in.
Mini-chart 1: How often outputs are reviewed
Share of orgs (genAI users):
Review all outputs ............. █████████ 27%
Review ≤20% of outputs ......... ████████ ~27%
Everything in between .......... █████████████████ 46%
Source: McKinsey Global Survey on AI (2025)
Perceived productivity—and the over-reliance trap
Users report speed gains and lower mental load on drafting and summary tasks. In enterprise surveys, leaders who redesign processes (not just bolt on tools) report the greatest financial impact. But the same data show gaps: many organizations still lack consistent review, do not track accuracy at the task level, and do not define where the model may recommend vs. decide. Those are the conditions where automation bias—the tendency to favor machine output even when wrong—shows up.
Trust is fragile. Edelman 2025 finds low, uneven trust in AI, with developed markets like the U.S. among the most skeptical; trust is higher where people see transparent governance. The Bentley-Gallup data echo this: 77% of Americans don’t trust businesses to use AI responsibly, but majorities say clear disclosure would ease concern.
Sidebar: How often does it “hallucinate,” really?
There isn’t one number. “Hallucination” depends on task, prompt, data grounding, and scoring method. Public leaderboards that test “groundedness” across models show non-trivial hallucination rates persist even for frontier models, especially when the model is asked to generate facts without retrieval or stretch beyond context windows. The Vectara Hallucination Leaderboard and similar evaluations illustrate how rates vary by prompt style and domain. The bottom line: without retrieval and clear sourcing, you must expect fabrication and design for it.
Why Our Brains Want AI to Be a Person
We don’t just use computers; we respond to them. Decades ago, Joseph Weizenbaum showed how users attributed understanding to a simple program (ELIZA) that mirrored their words back. Today, fluent LLMs amplify that pull.
Byron Reeves and Clifford Nass called it the Media Equation: people treat media as if it were human. Polite computers get treated like polite people. A voice that sounds warm feels trustworthy. None of this means the system is a person; it means we act as if it is, especially under time pressure.
Two mental systems shape what happens next. System 1 is fast, fluent, and effortless; System 2 is slow, careful, and tiring. Generative models create high-fluency text that slides into System 1. When output feels right, we accept it. That’s cognitive ease. But ease is not accuracy. We need guardrails that pull us back into System 2 when stakes are high.
Other biases are at work:
- Hyperactive agency detection: in ambiguity, we over-detect agency (“something with intent did this”). That once kept us safe; now it nudges us to see mind in a model’s polished prose.
- Need for cognitive closure: uncertainty is uncomfortable; a confident answer reduces it, even if wrong.
- Illusory truth effect: repeated statements feel truer, which matters when models restate claims across drafts.
- Illusion of explanatory depth: we think we understand more than we do; autocomplete makes us feel smart, masking gaps.
- Parasocial and social-surrogacy effects: responsive agents can feel like companions; that comfort can blur judgment.
At work, those forces meet real constraints: KPI overload, scarce coaching, and not enough time. When deadlines are tight, fluent output feels like progress. That’s when the slide from assist to delegate happens—unless leaders define clear boundaries and teach teams how to slow down at the right moments.
No, AI Shouldn’t Run Your Life (or Your Company)
The claim we must refute is simple: “AI is now good enough to act as a responsible proxy for major life or business decisions.” It’s not. Models predict text; they do not assume duty of care. They lack situational awareness, can be prompt-injected, leak, memorize sensitive data, and hallucinate with confidence—especially outside their training distribution or when adversaries try to bend them. Even when answers are right, accountability is thin: who is responsible if a model’s advice harms a patient, customer, or borrower? Technical capability does not equal moral or legal responsibility.
Below are brief mini-cases that show the gap between useful assistance and responsible judgment:
1) Legal work: hallucinated citations → court sanctions. In Mata v. Avianca (S.D.N.Y., 2023), lawyers who relied on ChatGPT were sanctioned after the model fabricated case citations that looked real. The court stressed the duty to verify. Even with better models, the rule stands: the drafter owns the filing.
Root cause: automation bias plus a failure to check sources.
Preventive controls: mandatory citation verification workflows; tools that link every claim to sources; escalations for missing provenance.
2) Consumer support: airline chatbot gives wrong policy advice. In Moffatt v. Air Canada (B.C. Civil Resolution Tribunal, Feb 2024), the tribunal held the airline liable for misinformation its website chatbot gave to a grieving passenger seeking bereavement fare guidance. The company argued the chatbot was a separate “entity”; the tribunal disagreed. The business owns its bots.
Root cause: unsupervised deployment; lack of clear disclaimers; no escalation to a human for policy-sensitive queries.
Preventive controls: risk tiering for customer-facing topics; Human-In-The-Loop on policy or compensation; logging and rapid correction.
3) Search-like features: persuasive phrasing, brittle facts. When generative “overviews” answer as if authoritative, small prompting quirks or weak retrieval can produce confident nonsense at Internet scale—a dynamic widely documented by independent evaluators and incident catalogs. Leaderboards that score “groundedness” show variability across models and tasks; factuality depends on retrieval and source quality, not eloquence.
Root cause: ungrounded generation; users reading fluency as truth (cognitive ease).
Preventive controls: retrieval-guarded generation; source display by default; rate-limits on unsupported claims.
4) Health: evolving guidance, shifting risk—and regulators stepping in. The FDA’s 2025 draft guidance for AI-enabled medical device software emphasizes lifecycle management, transparency, and submission expectations because adaptive systems pose special risks in clinical use. Translation: high-stakes advice demands strong process and human oversight.
Root cause: distribution shift and silent updates that change behavior.
Preventive controls: change-control, post-market monitoring, and clinician oversight consistent with FDA expectations.
5) Enterprise: governance gaps drive inconsistent controls. Surveys show rising adoption and uneven guardrails: only about a quarter of companies that use genAI say they always review outputs; a similar share check almost none. That’s not responsible decision-making—it’s a recipe for drift.
Root cause: lack of decision rights, HITL standards, and measurement.
Preventive controls: the Leader’s Playbook that follows.
Steel-man the counterview. Proponents argue models now beat humans on select benchmarks, write code, and summarize huge corpora. All true—and it’s helpful. But benchmarks aren’t duty of care. High-stakes decisions require context, accountability, and recourse. That still sits with people.
Leader’s Playbook: Prevent AI Over-Reliance at Work
Your goal is to unlock speed without outsourcing judgment. That takes clear decision rights, Human-In-The-Loop standards, policy, controls, training, and change-management. The following templates are designed for enterprises and easily tightened for regulated teams.
1) Decision Rights & Risk Tiers (R/A/G)
Use a simple Red / Amber / Green matrix that maps what the model may do (Draft, Recommend, Decide) by risk and context. Keep it in every team’s handbook.
DECISION MATRIX for GenAI use in daily work
| Risk Tier | Example(s) | Model’s Role | Human Role |
|---|---|---|---|
| Red / High | Legal filings; HR actions; pricing approvals >$50k; | Draft Only with sources | Owns decision; verifies sources; documents rationale; 2-person check |
| Amber / Medium | Customer emails on policy; product copy; internal policy and summaries; code that touches prod systems | Recommend with citations | Approver review of evidence; Edit for accuracy and tone; Final sign-off |
| Green / Low | Brainstorming; Rough drafts; Internal Notes; Non-user-facing code snippets | Decide within guardrails | Reviewer spot-check of samples; Escalation if output affects customer or data |
Map to RACI/RAPID: the model can Draft or Recommend—never Accountable. Accountability remains with the named human. (NIST’s AI RMF calls for differentiated human-AI oversight. Align your matrix to that principle.)
2) Human-In-The-Loop Standards (when, who, how)
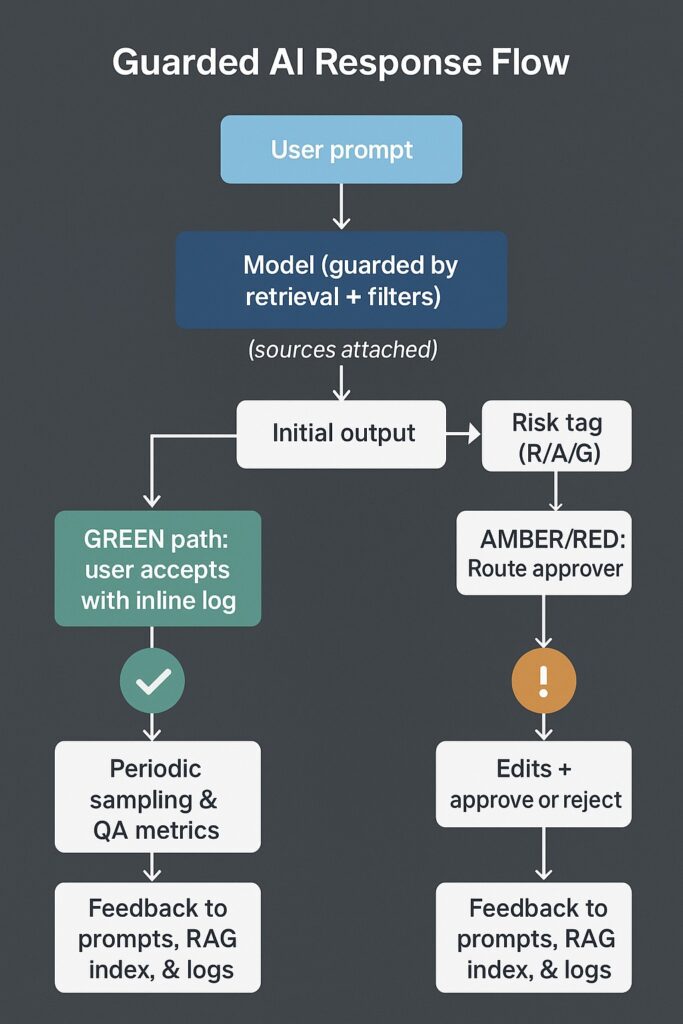
Review thresholds.
- RED: 100% review and approval by qualified staff; two-person integrity for irreversible actions.
- AMBER: pre-use review by the owner; aim for ≥80% sample checks each sprint; escalate exceptions.
- GREEN: post-use sampling (e.g., 10–20%); log issues to drive prompts and retrieval updates.
Exception queues. Any output lacking sources, touching PII, or contradicting policy goes to an exception queue with SLA (e.g., 24 hours) and named approver.
3) Policy Language Starters
Keep it short, clear, and visible. Derive from NIST’s AI Risk Management Framework and Generative AI Profile; localize to your sector.
- Acceptable Use. AI may draft and recommend; it may not decide in RED contexts.
- Data Handling/PII. Only use approved connectors; no pasting PII, PHI, or customer secrets into unmanaged tools.
- Prompt Hygiene. Avoid sensitive inputs; prefer templated prompts with retrieval; ban “role-play” that simulates people.
- Citations. Outputs that state facts must include source links; no source, no use.
- Logging. All prompts/outputs for business use are logged; teams review samples weekly.
- Incident Reporting. Misleading or harmful outputs are incidents; report within 24 hours; security reviews prompt-injection attempts.
- Change Control. Model or retrieval index changes follow release management; high-risk flows require stakeholder sign-off.
4) Controls & KPIs
Controls
- Guarded generation: retrieval-augmented answers with source display by default.
- Content filters: block sensitive topics, policy-risky actions.
- Role-based access: RED actions require elevated roles; service accounts, not human tokens, for automation.
- Version inventory: track model versions, indexes, prompts, and fine-tunes; freeze for audits.
- Adversarial testing: red-team for prompt injection and data leakage; rotate canary prompts. (NIST’s GAI Profile lists common attacks and mitigations.)
Metrics
- Accuracy sampling rate (by task class), hallucination rate, time-to-correction, citation coverage (% outputs with sources), exception rate, customer harm flags, training completion (% workforce).
- Review coverage: RED=100%, AMBER≥80%, GREEN sampling ≥10%.
- Over-reliance signals: unchanged prompts with heavy copy-paste; low edit distance; rising skipped-review counts.
5) Training & Change-Management
Your people must recognize cognitive traps. Train on automation bias, cognitive ease, illusory truth, and prompt-injection awareness with grounded exercises. Use short, frequent sessions and manager-led coaching. (Public trust improves when governance is visible and explained; design training as trust-building.)
Rules of thumb
- “Never personify the model”: say “the model outputs,” not “the model thinks.”
- “No source, no shipment”: if customers or regulators will see it, show your receipts.
- “Green by default, Red by design”: push work to Green; earn your way to Amber/Red with evidence.
6) Tooling guardrails
Use tools that force better behavior: source-pinned RAG, watermarking/disclosure for AI-assisted content, PII classifiers, and sandboxed connections. Align with NIST AI RMF categories (Govern/Map/Measure/Manage).
7) Mortgage-lending callout (regulated example)
In U.S. mortgage lending, disclosure accuracy, AUS submissions, and doc-compare are excellent assistive tasks for genAI. But final approvals and borrower-facing commitments must stay human, because compliance, fair-lending obligations, and rep-and-warranty risks rest with the lender—not the tool. Treat disclosures and conditions as RED: the model drafts with sources; a trained human verifies every claim before issuing to a borrower.
Conclusion & Call to Action
Generative AI is a power tool, not a proxy for judgment. It writes fast, remembers patterns, and never tires. It also hallucinates, misreads edge cases, and can be manipulated. Our minds are wired to treat fluent outputs as true and to offload hard thinking under pressure. That is why leaders must set bright lines now.
Make it easy to do the right thing: a R/A/G matrix taped to every monitor, HITL built into the workflow, sources by default, training that names the bias, and metrics that catch drift. Borrow trust from recognized frameworks (NIST AI RMF; FDA’s lifecycle view in clinical software), then show your work to your teams and customers.
If you do, you’ll get the good—speed, clarity, pattern-breaking ideas—without handing your reputation to a stochastic parrot.