
August 28, 2025
Stop Automating “Mortgage.” Start Automating Tasks.
Executive Summary
Most “AI in mortgage” pitches skip the hard part: the specifics of individual tasks—when they start, which inputs they need, which rules apply, and how exceptions derail automation. This article proposes a concrete, repeatable method to score automatability at the task level, applies a Decision Rights & Risk overlay to determine how much human-in-the-loop (HITL) is required, and explains why Brimma prioritized document automation first: high impact, clear triggers, codifiable rules, and minimal HITL.
To a large extent, this article draws from the article titled Why AI experts get their predictions on jobs so wrong”” on the AI Supremacy website. It also draws from our previous article “Why We Keep Treating AI Like a Person—and Why It Shouldn’t Run Our Lives (or Our Companies)”.
Section 1 — The Problem with Hand‑Wavy AI
Saying “AI can automate mortgage” is meaningless unless you define the task, the trigger, the inputs, the business rules/overlays, and the exception paths. Without all of these, your ability to successfully use AI and/or automate your process is severely limited. But that was also true before AI. So what makes anything different given the advancement of reliable AI?
The answer: Everything.
The core premise of this article is to illustrate that the way you think about tasks and workflow is grounded in the technology you currently have. AI has opened-up entire new areas to automation. Rather than trying to apply AI to fix existing holes and inefficiencies, you should consider the sizeable gains that are possible if to start with a blank page.
OK, I know I just lost you on that one…no one has the time to start with a blank page! That’s why this article shows you how we have combined our decades of technology experience with our AI thought leadership to provide you a framework for automating your tasks in an AI-enabled world!
Before we launch into the details, can we all please agree that vague statements about “AI can fully automate disclosures” or “AI can automatically underwrite your loan” are completely worthless sales pitches? Whenever someone makes such a claim, it usually takes us about two minutes to find a ton of exceptions that fall outside of the automation. Why? Because they saw the happy-path and said “I can automate that” without regard for the complexity of the business’ real needs. If your disclosure automation doesn’t revalidate all of the underlying loan data, check pricing against tolerances, verify fees are accurate and ensure a clean compliance report, then is it really helping you?
Section 2 — A Practical Framework for Task‑Level Automatability
Task‑level automation only works when every candidate task is understood along four dimensions. We score every task on each dimension using an equal-weighting rating from 0-3. We keep the scale consistent so teams can compare unlike tasks without hidden weighting—no dimension is more important than another in the abstract. Instead, the balance of scores tells you where to start and what guardrails you’ll need.
This framework is the result of years of mortgage process workflow work combined with an realistic assessment of what AI is able to reliably do today. If you don’t want to geek-out on these details, feel free to skip to the next section where we start to talk about how we took our decades of knowledge on all of the tasks you likely face and started to (re)organize them based on this framework.
Triggerability. The first question is whether the system can know, deterministically, when it’s the right time to start the task. A low score means start conditions are ambiguous or human‑interpreted (emails, ad hoc notes, tribal knowledge). A high score means there are clear, machine‑detectable events—milestone changes, document‑ingestion events, pricing deltas, or pre‑validation passes—that act as clean triggers. Triggerability matters because even perfect downstream logic fails if you can’t reliably press “go.”
Again, the scoring you will see below is based on AI’s current capabilities, but this particular area is likely to continue to expand as AI integrations deepen and more of the ambiguous triggers can be captured by AI.
Input Complexity. This gauges how many inputs are required and how messy they are. A low score implies a short list of structured fields pulled from the LOS or PPE. A high score means multiple sources, unstructured documents, and cross‑system lookups. Input Complexity matters because every additional source or document class multiplies the chances of mismatch, missing data, and latency. Models can help, but entropy in the inputs is the fastest way to erode precision and speed.
This dimension is also quite interesting wrt AI as one of AI’s strengths is to apply structure to unstructureed items. You’ll see below that this weighed heavily in our consideration for where we started our own automation products.
Rule Complexity. Here we assess the determinism and volatility of the logic you must apply. A low score means stable, explicit rules. A high score reflects multi‑investor overlays, frequent updates, and interactions among conditions (product, geography, property type…we actually track 22 dimensions that are most likely to affect rule complexity!). Rule Complexity matters because automation depends on rules being executable at scale, and on having versioning that keeps you current without breaking historical decisions.
Exception Volatility. This measures how often and how unpredictably edge cases show up, and how ambiguous their resolution is. A low score suggests rare, well‑contained exceptions with obvious next steps; a high score indicates frequent, diverse exceptions that demand judgment, borrower outreach, or vendor coordination. Exception Volatility matters because it sets your human‑in‑the‑loop load and determines whether automation will actually free capacity or just move work around.
If you ever implemented RPA (Robotic Process Automation), you might have fell victim to poor planning on this dimension. If your automations needed constant human attention (which sort of defeats the purpose), then there was likely too little upfront consideration of the number and complexity of exceptions that could occur.
When you score a task across these four dimensions, you translate the pattern into an Automation Tier: T0 (Manual), T1 (Assisted), T2 (Human‑in‑the‑Loop), or T3 (Lights‑Out). The tier isn’t a fifth dimension; it’s the operating mode that falls out of the scores.
But these four dimensions are not sufficient to determine automatability in an AI world. Finally, we apply a Decision Rights & Risk overlay—our Red/Amber/Green model—to specify whether the AI model should be trusted to Decide, Recommend, or Draft, and the minimum review cadence. For a deeper dive on that overlay, see our companion Brimma article on decision rights and risk; here, we’ll reference it without retelling the whole story.
Section 3 — Reorganize Work, Not Headcount
AI doesn’t replace whole people; it rearranges the flow of tasks. Humans handle exceptions, judgment, and relationships while AI executes the repeatable parts with speed and consistency. The shift is from milestones to signals (event‑driven triggers), from roles to routers (send work to the right handler based on task and exception label), from hunters to reviewers (machines assemble the packet; humans confirm), and from static policies to enforceable overlays (risk and HITL live in the workflow).
What makes this workable is that we’ve done the taxonomy work upfront. We standardize task types and exception labels—Data‑Mismatch, Eligibility‑Overlay, Tolerance‑Breach, Consent/Disclosure‑Gate, Provider‑Latency, Collateral‑Anomaly, Identity/Fraud‑Flag, Lock/Rate‑Window—so routing, dashboards, and SLAs are consistent across teams. That clarity is what underpins the quadrant view of your operation.
To be clear, we are not presenting you with a workflow. We are presenting you with an alternate way to envision what your workflow could look like and how you ought to prioritize your transition to whatever works best in your organization. We think that smarter mortgage minds than ours can leverage this framework to create optimized workflows. We know of at least one form where they have unleashed tasks and infused AI to create an “off the shelf” mortgage process that leaves room for you to blend in your secret sauce. Ping us for the details!
Section 4 – Four Quadrants Decisioning Tool
We bumped our long list of mortgage origination tasks against this framework and scored every task on each of the four dimensions. We took the resulting Automatability Tier and charted it against the AI Risk. This gives us the 4-qudrant decisioning framework below. Note that for brevity (and because we can’t give you all of our insights unless you at least say “hello”) we are only including a subset of the total task list.
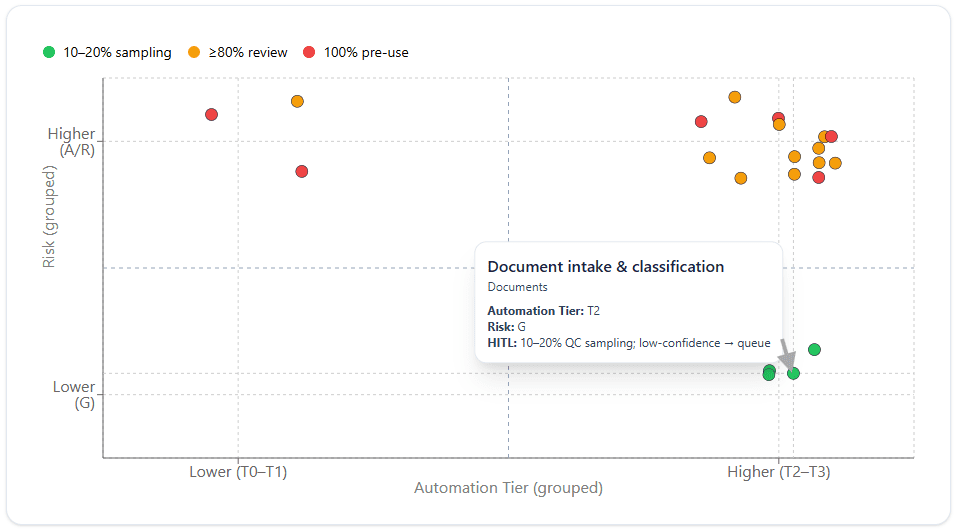
Before we go deeper, here’s how to read the quadrant chart:
- High Automation × Low Risk [BOTTOM-RIGHT] holds your quick wins: document intake/classification, title ordering, LOS–CRM sync. These are great candidates for “Green/Decide” with sampling QC.
- High Automation × High Risk [UPPER-RIGHT] is where guardrails pay off: compliance rechecks, redisclosures, AUS orchestration. You can automate aggressively, but Decision Rights/Risk dictates stronger and possibly perpetual HITL.
- Low Automation × High Risk [UPPER-LEFT] remains draft‑oriented: CD prep/balancing, funding/wires. Automation assembles, humans decide to ensure you are not over-exposed to AI risks.
We omit or lightly populate Low Automation × Low Risk because those tasks are either trivial or already automated; they rarely warrant investment.
Human‑in‑the‑Loop Isn’t One Thing
HITL comes in flavors. For our 4-quadrant diagram, it comes in colors.
GREEN = Up‑front only means you review outputs intensively at launch, then taper to sampling as confidence rises. Ongoing sampling means a steady 10–20% QC on Green/Decide tasks.
ORANGE = Gate reviews require approvals only at specific control points (e.g., redisclosure timing, wire release).
RED = Dual control applies where actions are irreversible. When the result of an error is high enough, you mandate HITL….even with the best AI.
The point is to right‑size human involvement by risk tier and evidence quality, not to bolt a human onto every step. We anchor these choices to the Decision Rights & Risk model detailed in our companion Brimma article.
Section 5 — Why Documents First (Brimma’s Choice)
We highlighted one of our first choices for AI automation, document intake and classification. Let’s simultaneously show you why it falls where it does in the quadrant while also giving you our rationale for starting here.
First, the straight-forward rationale:
- High Triggerability: “New document received/classified” is a clean event.
- High Impact: Nearly every loan has tens if not hundreds of documents; any successful automation can be translated into tangible ROI.
- Time‑to‑Value: Quick wins without ripping-out the LOS; documents naturally lend themselves to “use cases”. You can start in a single area (borrower ID docs) and then move on to others.
- Low HITL: While you could make the argument that mortgage is fraught with poor-quality and one-off versions of documents, those actually turn out to be a very small percentage of the documents received. As a result, with some planned upfront QC sampling plus the ability to filter the technology based on confidence thresholds leads this to be a relatively positive aspect of its automatability. Additionally, the most obvious excepotions aleardy fit into a common workflow pattern that can be leveraged: stare-and-compare.
What’s starts to really tip the viability in favor of starting with documents is that it can act as an improvement on the automatability of so many other tasks. More specifically, automation that ensures the data from documents is accurately applied to the loan file and is checked for validity against the LOS and other documents drives higher quality data into all of the tasks that need reliable, high-quality data to be automatable. Remember our Input Complexity measure? Solving document classification and doing full AI validation REDUCES that complexity for a host of other tasks (e.g. income/DTI calculations).
What we implemented:
Notice when we talk about where we started, we have been very particular to mention that our goal was to VALIDATE documents. Old technology was happy to be able to determine the document classification 80% of the time and to be able to extract quality data from those documents 80% of the time (for a whopping 64% coverage!). AI document intelligence has dramatically increased both of these accuracy rates AND can reliably give you confidence factors so that not every “miss” is necessarily a failure.
This is why a blank slate for your new operating model is so important. AI has opened-up several new tools that can reshape how you organize work.
So one of our first endeavors was to provide a full string of automations that:
- Intake documents → classify → extract data → validate vs loan data and against other documents → automate‑actions (update LOS, set statuses, trigger workflows)
The obvious outcomes have been faster cycle times, fewer touches, fewer tolerance/redisclosure surprises, clearer audit trails. The more interesting aspect has been that we have identified MORE tasks for humans.
Hold it, what? It’s a success to have created more human tasks??? Yes!!!
Whereas almost every document workflow today routes any document issue to a single stare-and-compare queue based on the document type, we can differentiate by the specific risk rating of each validation failure what skill level is required. Here are some examples:
- A bank statement is found to be missing pages -> sent to queue to automatically re-request corrected bank statement from borrower
- A bank statement is found to have a Buy-Now-Pay-Later payment on it – > Queue-up alert so Underwriter is made aware
- The name on a bank statement does not match the borrower’s name -> send to a queue for a low cost resource to stare-compare and determine whether name difference is problematic
At scale, this kind of differentiation adds up to big efficiencies. Even if you are not a large lender, if you outsource task work, you can realize similar cost benefits.
Section 6 — The Exception Taxonomy (Start Here, Not Last)
Exceptions are the hardest part of automation.
Think 80/20 rule: the happy path 80% may take only 20% of the effort to automate. The last 20%—your exceptions—will consume the other 80% of your effort.
If you start without mapping the known exceptions, you’re betting your ROI on unknowns.
We’ve learned the hard way to begin every engagement by enumerating exception classes, estimating their frequency, and defining their default next actions and SLAs. That makes it possible to predict where human capacity will be needed and whether “lights‑out” is realistic.
Our baseline exception categories include:
- Data‑Mismatch (application vs. docs vs. third‑party)
- Eligibility‑Overlay (investor/product conflicts)
- Tolerance‑Breach (TRID fee tolerances/redisclosure)
- Consent/Disclosure‑Gate (e‑consent missing, ITP not captured)
- Provider‑Latency (title/appraisal/VOE delays)
- Collateral‑Anomaly (waivers, valuation flags)
- Identity/Fraud‑Flag (OFAC/fraud alerts), and
- Lock/Rate‑Window (lock expiring, pricing moved).
We don’t just label them—we’ve framed remediation patterns and routing rules for each, so exceptions move forward, not sideways.
Section 7 — Partnering with Brimma (Apply This to Your Stack)
You already run the tasks we’re describing—and we’ve already scored them. We know where AI is strong, where risk demands guardrails, and how to wire event triggers without forcing a core‑system replacement. Our engagement focuses on three outcomes:
- Prioritize the right tasks for your volumes and product mix using the 0–3 scoring model. Want to see our full classification of every task we’ve ever seen? Reach-out!
- Embed decision rights and HITL into your workflows so compliance and audit are built‑in, not bolted‑on.
- Deploy the right tech—document automation first (Vallia DocFlow), then orders, (re)disclosures, integrations, and delivery—without shoehorning AI into legacy patterns that fight it.
If you want speed without regret, start where the signals are clean (documents), prove it with metrics, and expand from there—with Brimma as your guide.