
April 14, 2025
An AI LLM Primer & Why You Might Care
Last updated: 14 April 2025
1. Why Does Every AI Company Name Models Like Smartphone Releases?
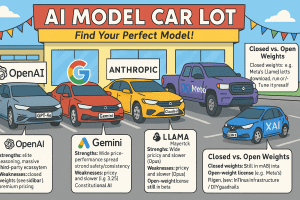
Because they can—and because customers want different mixes of cost, speed, and brain‑power. Picture the car lot: zippy hatchbacks (mini models), sensible sedans (balanced midsizers), and monster trucks (flagships that climb mountains but guzzle GPU hours). OpenAI’s o‑series, Google’s Gemini lineup, and Meta’s Llama family all follow that playbook. One‑size‑fits‑all is officially dead.
2. Meet the Families
OpenAI
OpenAI’s headliner is GPT‑4o—the “o” allegedly stands for “omni,” though some insiders swear it means “oops, we made GPT‑4 obsolete.” It out‑wits GPT‑4 while running about twice as fast. Beneath it sits the o‑series (o1‑mini, o1‑pro) for high‑volume tasks, plus the stealthy GPT‑4.5 that bridges the gap to GPT‑5. Expect older models to disappear quickly—GPT‑4 bows out on 30 April 2025. Note though, GPT4 <> GPT4o !
Note that OpenAI uses closed weight models, which can be a key factor in model selecton.
Sidebar — Closed vs. Open Weights
Closed weights mean the model’s parameters stay on the vendor’s servers; you get an API key, not the recipe.
Open‑weight license (e.g., Meta’s Llama) lets you download the model and run or fine‑tune it yourself—though “open” doesn’t always equal fully open‑source.
Strengths: elite reasoning, massive third‑party ecosystem.
Weak spots: closed weights (see sidebar), premium pricing, rate‑limit whiplash.
Google | Gemini
Gemini looks like a nesting‑doll set: 1.5 Flash, 1.5 Pro, 2.0 Flash, and now a 2.5 Pro preview bragging about a one‑million‑token context window.
Sidebar — Context Windows
“Context” is the amount of text the model can keep “in mind” at once. A one‑million‑token context window is roughly 700 000 words—War and Peace plus a decent stack of emails. This may sound like a lot…and it is…but when you are trying to load the entire context of an investor’s guidelines along with a complex loan’s MISMO data, you might find how fast you can use it up!
In the cheat sheet below, Context Max shows each model’s advertised ceiling.
Gemini is baked into Gmail, Docs, and Android—expect to bump into it whether you want to or not.
Strengths: deep Workspace hooks so it’s great for Google platform users, bargain pricing on Flash.
Watch‑outs: naming chaos; Google occasionally swaps model aliases overnight and breaks reproducibility.
Anthropic | Claude
Anthropic plays the “ethical big sibling” with Claude 3—Haiku, Sonnet, and Opus. Their secret sauce is Constitutional AI.
Sidebar — Constitutional AI
Anthropic trains the model to follow a written “constitution” of rules and values, so instead of hard‑coded filters you get consistent, explainable guardrails.
Opus tops academic benchmarks, though your accountant may wince at the bill.
Strengths: Wide price‑performance spread (Haiku → Opus), roomy context windows up to 1 M tokens, high factual accuracy, strong safety/consistency from Constitutional AI, and multimodal support at the top tier.
Weaknesses: Opus is pricey and slower, Haiku can be shallow on complex reasoning, stricter refusals due to guardrails, closed‑weight licensing, and still trails GPT‑4o on the heaviest coding/math tasks.
Meta | Llama
Meta unleashed Llama 3 in 2024 and doubled down with Llama 4 this month. The open‑weight Scout variant fits on one GPU and digests ten million tokens, while Maverick—an MoE giant—claims GPT‑4‑level chops without the OpenAI sticker shock.
Sidebar — MoE (Mixture of Experts)
Instead of one massive neural network, an MoE model routes each prompt to a handful of specialized “experts,” giving more brains only when needed. Result: heavyweight performance, lightweight inference costs.
If you’re willing to run your own infrastructure (and tame your own guardrails), Llama is the rebel’s choice.
Strengths: Open‑weight license gives you full model files to self‑host or fine‑tune; zero per‑token vendor tax once deployed. Scout fits on a single GPU while Maverick’s MoE design delivers near‑GPT‑4 power at bargain inference cost. Huge grass‑roots community, lightning‑fast third‑party tooling, and long context windows (up to 10 M tokens in Scout) make experimentation easy.
Weaknesses: You’re on the hook for infrastructure, scaling, and security—no turnkey SaaS safety net. Guardrails are DIY, so compliance teams may frown. Model checkpoints and forks can be fragmented, leading to version confusion. Performance on niche coding/math still trails GPT‑4o, and official multimodal support lags closed‑weight rivals.
xAI | Grok
xAI’s Grok‑2 (and pint‑sized Grok‑2 mini) still feels like a public beta, but it’s already nipping at GPT‑4‑Turbo on benchmarks. Its party trick: native access to real‑time X/Twitter data—ideal if you want an AI plugged into the firehose of hot takes.
3. Cross‑Model Cheat Sheet
| Vendor | Flagship (Apr 2025) | Context Max | Multimodal? | License | Party Trick |
|---|---|---|---|---|---|
| OpenAI | GPT‑4o | 256 K | Text, vision, audio | Closed | Top‑tier reasoning & coding |
| Gemini 2.5 Pro | 1 M | Text, vision, audio | Closed | Seamless Workspace embed | |
| Anthropic | Claude 3 Opus | 200 K (1 M preview) | Text, vision | Closed | High factual accuracy |
| Meta | Llama 4 Maverick | 128 K (10 M Scout) | Text, vision | Open‑weight | Self‑host & fine‑tune |
| xAI | Grok‑2 | 200 K | Text, vision | Closed | Real‑time social data |
Numbers are vendor‑supplied; salt to taste.
4. Why Bother Following More Than One Model?
We happen to prefer Microsoft technology and, at least as of today, that translates mostly to OpenAI. We get asked all of the time, “Did you consider other models?” Sure, we considered them, but at some point you need to actually “code” and it’s a lot of work to try to train multiple models simultaneously.
So why should you pay attention to what is going on with all of these models?
First, outages happen—ask anyone who launched a product during a GPT hiccup. Second, pricing varies wildly: draft with a cheap Flash model and let a premium model polish the prose. Third, features differ: Gemini devours long context, Llama keeps data on‑prem, and Claude politely refuses to hallucinate as often. Finally, regulators are getting nosy, and open‑weight models might save your bacon when data‑sovereignty lawyers come knocking.
Oh, and you no longer need to pick a single vendor. Toolkits and platforms like LangChain, LlamaIndex, Vercel AI SDK, Amazon Bedrock, Together AI, OpenRouter, and Anyscale Endpoints act as overlays, letting you hot‑swap models behind one API call—kind of like switching streaming services without changing the remote.
5. Where Is This Circus Headed (Next 6‑18 Months)?
Multimodal by default. Text‑only is so 2023; expect models to juggle audio, video, and maybe holograms.
MoE everywhere. Meta’s expert‑mixture architecture hints at smaller, cheaper models that punch above their weight.
Regulatory splintering. EU AI Act compliance will spawn regional variants—think GDPR, but for neural nets.
LLMs as OS features. Apple, Microsoft, and Google are quietly baking assistants into the operating system itself; soon choosing an LLM might feel like choosing a default browser.
TL;DR
Model choice is becoming as routine—and as political—as picking a cloud vendor. Keep a diversified AI portfolio, watch the roadmaps (they change faster than TikTok trends), and don’t underestimate the open‑weight upstarts. The next year will be loud, chaotic, and occasionally brilliant—strap in.
Reference Sources For This Article
- Anthropic – Claude 3 Model Card (Haiku, Sonnet, Opus)
https://www.anthropic.com/claude-3-model-card - xAI – Grok‑2 Beta Release Post
https://x.ai/blog/grok-2 - OpenAI – GPT‑4o Release Notes
https://help.openai.com/en/articles/9624314-model-release-notes - OpenAI – Model Deprecations & GPT‑4 Retirement Notice
https://platform.openai.com/docs/deprecations - Google Cloud – “Gemini 2.5 Pro & Flash Preview on Vertex AI”
https://cloud.google.com/blog/products/ai-machine-learning/gemini-2-5-pro-flash-on-vertex-ai - Google Cloud – Vertex AI Generative‑AI Pricing Page
https://cloud.google.com/vertex-ai/generative-ai/pricing - Meta AI Blog – “Introducing Llama 4: Scout and Maverick”
https://ai.facebook.com/blog - TechCrunch – “Meta Releases Llama 4, a New Crop of Flagship AI Models”
https://techcrunch.com/2025/04/05/meta-releases-llama-4-a-new-crop-of-flagship-ai-models/ - Barron’s – “Meta Upgrades Llama AI as Tariffs Hit Tech Stocks”
https://www.barrons.com/articles/meta-stock-upgrade-llama-ai-f2333776 - European Parliament – Artificial Intelligence Act Press Release
https://www.europarl.europa.eu/news/en/press-room/20240308IPR19015/artificial-intelligence-act-meps-adopt-landmark-law - LangChain Documentation – Introduction
https://python.langchain.com/docs/introduction/ - LlamaIndex Documentation – Home
https://docs.llamaindex.ai/ - Vercel – AI SDK Overview
https://vercel.com/docs/ai-sdk - AWS – Amazon Bedrock Service Page
https://aws.amazon.com/bedrock/ - Together AI – Models Catalog
https://www.together.ai/models - OpenRouter – Home / Unified LLM Interface
https://openrouter.ai/ - Anyscale Docs – Endpoints Introduction
https://docs.anyscale.com/endpoints/intro/